
How-tos
Phonetic alignment
If you have suggestions on how to improve this document, or find mistakes, please send them to ilslabs@nulluu.nl
HQ 2022.02.09
Introduction
Phonetic analyses are accelerated considerably by means of so-called phonetic alignment. From an end-user perspective, this amounts to (a) the synchronization of a pre-existing orthographic transcription with the speech signal, (b) expansion of the orthographic transcription to dictionary pronunciation of each word in phonetic symbols, and (c) alignment or synchronization of each speech sound symbol to the corresponding part of the audio signal. The results are collected in a TextGrid, which can be read and used further (e.g. for analyses in Praat).
WebMAUS
The phonetic alignment is provided under the acronym “WebMAUS” by this web service.
Select the service ‘WebMAUS Basic’ from the ‘Service sidebar’ on the left-hand side of the home page
“This web service inputs a media file with a speech signal and a text file with a corresponding orthographic transcript, and computes a word segmentation and a phonetic segmentation and labeling.”
This document was prepared with version 3.9 of the WebMAUS service.
Before using the service, audio and text files need to be prepared, see details below.
Click in the file area, and select the associated audio and text files, see details below. Upload the files.
Choose the appropriate language (such as English-GB for BBC recordings of Shakespeare’s plays), and choose TextGrid as output format.
Accept the terms of usage, and press the big blue button “Run Web Service” under the checkbox.
After a waiting time (which may be several minutes for long audio files!), one or more resulting TextGrids appear in the output panel. Depending on your web browser, you may right-click on the TextGrid link, choose “Save…”, and save the TextGrid object into the same folder where you have the matching audio file (by the same name) and perhaps also the matching text file by the same name.
Input file preparation
As explained on the WebMAUS website, the audio file and text file to be aligned must have the exact same file name. The file NAME must not contain blanks or periods or hyphens (but underscore _ is OK). Use the appropriate extension for each file: DOC for formatted text, TXT for unformatted text, WAV for audio WAV files, etc. The audio file can be stereo or mono in any common format; if necessary it will be converted to mono during the MAUS process.
Make sure that the contents of the input files match exactly, i.e. all words in the text file must be in the audio file, and vice versa. Misalignment in the input files will result in misalignment in the output.
Output
“What you see [in the resulting TextGrid Figure 1] are three so-called ‘annotation layers’ (or ‘levels’ or ‘tiers’): word (ORT-MAU), standard pronunciation of the word (KAN-MAU) and phonetic segmentation (MAU, encoded in X-SAMPA).” For X-SAMPA, see wikipedia.
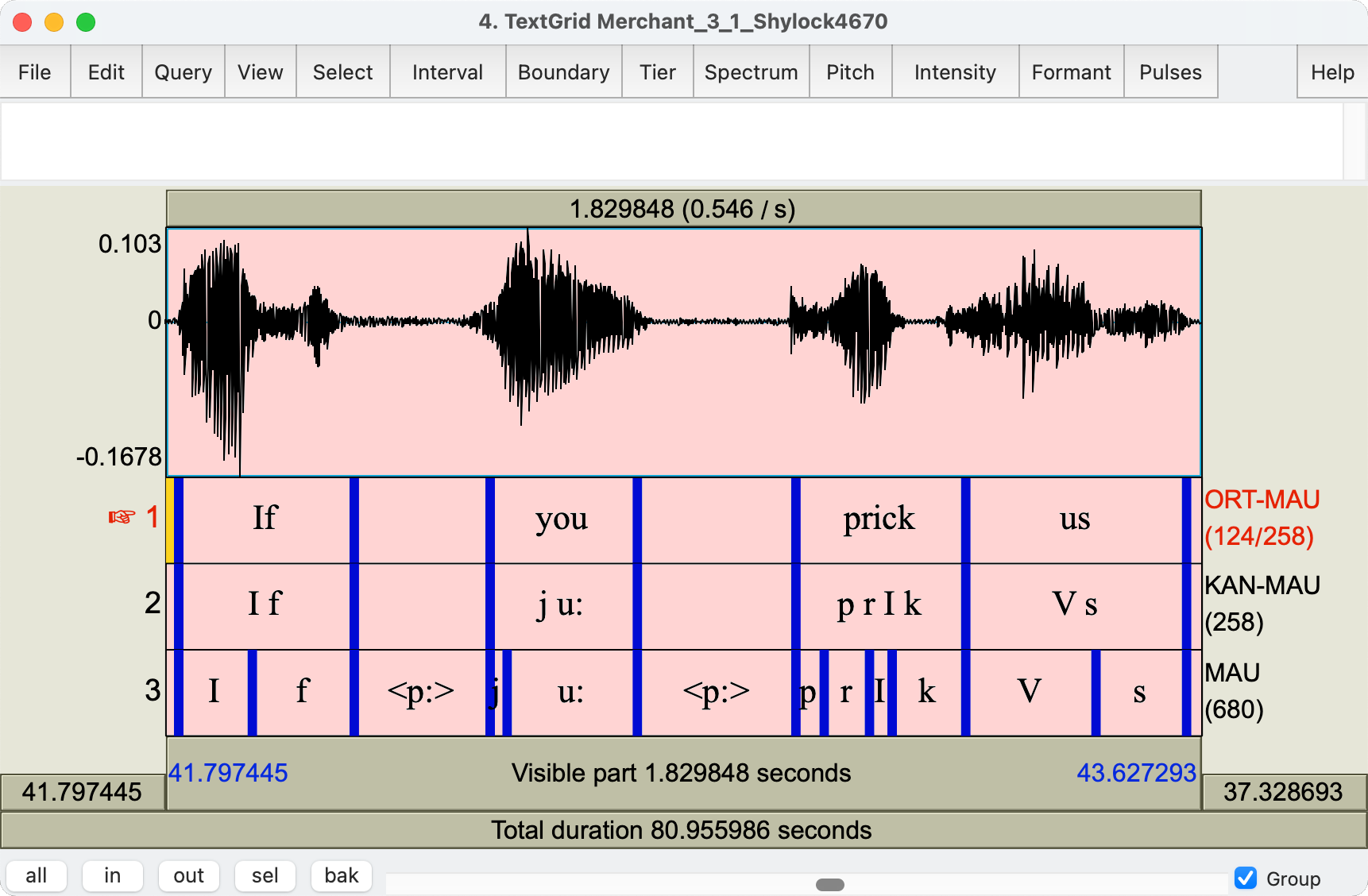
Errors
The resulting, aligned phonetic transcription in the downloaded TextGrid may well contain erroneous phonetic alignments, especially at places where the speech is interrupted by interjections, laughs, jeers, etc etc. These need to be corrected manually, by dragging the boundaries in the TextGrid.
In Praat, open or read, and then select, the appropriate and matching Sound and TextGrid objects. Then choose “View & Edit” to bring up an editor.
In the Editor Preferences, you can switch off the phonetic symbols; this will give you a better view of the audio and transcriptions.
For my example run, using the audio file Merchant_3_1_Shylock4670.wav and the text file Merchant_3_1_Shylock4670.txt, the processing described above resulted in an aligned transcription in a TextGrid named Merchant_3_1_Shylock4670.TextGrid. Errors occurred in those parts of the monologue where the protagonist’s speech is mixed with speech from others, e.g. during the fragments “mocked at my” and “as a Christian is”. MAUS will force-align the expected speech sounds in the given order to the audio signal, but the forced-alignment is incorrect in these two passages — and possibly in more passages.
You can fix such erroneous alignments by dragging the boundaries to their correct locations.
Remember to SAVE the updated TextGrid — Praat will NOT do that automatically! In the Praat Objects window, select the TextGrid object, then from the top menu choose “Save > Save to text file”.
Credits
Remember to cite the WebMAUS service in publications, as agreed in the terms of usage:
Schiel, F. (1999). Automatic Phonetic Transcription of Non-Prompted Speech. In Proc. of the ICPhS (pp. 607-610).
Kisler, T. and Reichel U. D. and Schiel, F. (2017): Multilingual processing of speech via web services, Computer Speech & Language, Volume 45, September 2017, pages 326–347.