Last updated on 11 April 2025 by Iris Mulders
If you have suggestions on how to improve this document, or find mistakes, please send them to ilslabs@nulluu.nl
Introduction
This page aims to give you a step-by-step guide to running your own readingVisual World Paradigm (VWP) experiment under Linux under Windows with the EyeLink 1000 in room K.12, booth 5. Technical details about this set-up can be found here on the facilities page. Baby EyeLink in room K.09. Technical details about this set-up can be found here on the facilities page. SMI RED250mobile eye tracker.
This page is always under construction. If you find mistakes or have things to add, please send them to Iris Mulders.
Recipe for a readingVisual World Paradigm (VWP) experiment
Step 1. Before you start
Support and opening hours
Equipment: architecture of the set-up
In remote mode, the EyeLink 1000 system samples one eye at 500 HzThe SMI RED250mobile eye tracker samples both eyes at 250Hz, using infrared video based tracking technology. Freedom of movement is 32 x 21 cm at a 60 cm distance; gaze position accuracy is 0.4 degrees. For a full technical specification of the SMI RED250mobile, see their product flyer.
The SR Research EyeLink 1000 System consists of a high-speed camera with an infrared illuminator, and two computers:
- EyeLink Host PC (in SR Research terminology: Host PC): controls the eye-tracking system and data sampling. The EyeLink Host PC was configured by the manufacturer, SR Research, and runs the software that controls eye tracking and data sampling. It contains routines to calibrate a subject and to calculate, visualize, and store on-line gaze positions. Gaze positions are corrected for (small) head movements through the use of a target sticker on the participant’s forehead; freedom of movement is 22x18x20 cm (horizontal x vertical x depth). The eye-tracking software on the EyeLink Host PC runs under DOS, and is rarely operated directly by the experimenter. During an experiment, the EyeLink Host PC is controlled by the experiment program ZEP.
- Stimulus PC (in SR Research terminology: Display PC): controls the presentation of stimuli and the acquisition of subject responses. The Stimulus PC is equipped with two monitors, one in the operator room and one in the participant booth. You can access the ILS Labs data server from the Stimulus PC. The Stimulus PC is a dual boot machine, offering a choice between Linux (default) and Windows.
The EyeLink Host PC and the Stimulus PC communicate over a (crossover, orangered) ethernet cable using SR Research software.
We have a special illuminator for use with infants under 9 months which may be installed if someone has been testing such young infants; always check that you are using the right illuminator (see Step 3 below).
The SMI setup consists of a laptop (running Windows 8), and the eyetracker itself, which is connected to the laptop through USB. The whole setup fits into a flightcase. We also have a small flat external USB-screen that you can use to monitor the participant’s gaze during the experiment.
Practicing camera setup and calibration
Step 4 outlines how to perform camera setup and calibration. Working with the equipment does require some instruction and practice; please read the information in Step 4, and contact Iris Mulders for a tutorial. Do this well before you are ready to start running your experiment!
Accessing scripts and data on other computers
The eye-tracking labThe SMI laptop is primarily meant for running experiments; you are expected to do some of your experiment preparation, and all of your data analysis, on other computers, outside the eye-tracking lab (for instance in our practicum room K.06, or at home). Use the ILS Labs data server to safely store your data, and to access your data on other computers.
Up to steps overview
Step 2. Create stimuli and implement your experiment.
Stimulus caveats for reading experiments
Before going into details of stimuli creation, some caveats regarding eye-movement measurement, stimulus presentation, and textual layout are in order.
The first warning is related to characteristics of the eye-tracker system. Although the system is capable of measuring eye movements over the complete range of the display, it is not advisable to perform critical measurements near the top, left and right display borders. Measuring near the display borders, where the limits of the system are reached, might lead to data loss.
The second warning pertains to the presentation of stimuli. When a text stimulus is presented to the reader, the eyes are often off-position. The reader will have to find the start of the first sentence before reading proper can commence. This seeking behaviour will influence the reading data on this region, causing less accurate measurements. The problem can be avoided, to some extent, by presenting a fixation point prior to the stimulus that marks the beginning of the text. This way, the eyes will already be in the vicinity of the start of the text. In the standard reading experiment discussed in this how-to, this fixation point doubles as a point where the system checks for drift (and prompts for a recalibration if necessary).
The third warning is related to characteristics of the reading process. When readers approach the end of a line of text, they prepare a large jump, a return sweep, to the beginning of the next line. The position of the launch site of a return sweep varies considerably, depending on reading efficiency, reading strategy, textual difficulty, word length, and other factors. Often, words at the end of a line of text are skipped. It is, therefore, unwise to make the end of a line of text a critical region of investigation. A similar problem occurs at the landing site of the return sweep. A return sweep often has an undershoot which is corrected by a small saccade to the left. The reading times associated with line beginnings, therefore, are contaminated with return sweep behaviour, causing an increase in variance.
In short, one should avoid presenting critical material near the display borders, at text start, and at line endings and beginnings. The optimal measurement position is near the center of the display.
Finally, it is unwise to offer very long texts (longer than, say, 40-50 words). Longer texts tend to lead subjects to scan the text rather than reading it from top to bottom and left to right. This will make your results hard to interpret. If you need to present long texts, consider breaking them up into multiple pages.
Technical implementation
It is recommended that you create and try out a few stimulus materials on the actual setup you will use to run your experiment, before you move on to creating all your stimulus materials on other PCs. This way you can sort out all technical details, before creating all materials in a potentially ‘wrong’ way. Get help from Iris Mulders or Maarten Duijndam the first time you work in K.12in K.09on the SMI laptop. They will also give you some pointers on how to work with the equipment; all of that information is also detailed in Steps 3-5 below.
In as far as you need to prepare your experiment on the SMI laptop itself, work in booth 6 in K.12 (or in a booth in K.10 if booth 6 is occupied for other experiments); do not take the setup home, or work with it in K.06.
Lab support will create a folder for you on the laptop’s desktop. Always work from there (consider it your home folder). Make sure to back up your work regularly to an external hard disk (you can borrow one from the lab if you don’t own one yourself). Make sure to encrypt sensitive information such as participant info and sound/video recordings.
In addition, periodically back up your work and data to your home folder or your project folder on the ILS Labs data server aka the O-drive. There is no convenient way to access the network from the SMI laptop, but you can plug in your external harddisk in room K.06 for instance and upload to the data server from there.
While you are preparing your experiment, it is best to work in a project folder on the ILS Labs data server aka the O-drive. Your work will then be backed up automatically, and you can easily work together with your supervisor and other people in your project, as well as work from home or in K.06 on the same experiment. (NB: Right now, running an experiment on the O-drive only works under Windows – we are working on a solution so that you can also prepare your experiment under Linux on the O-drive). You will eventually want to run your experiment with participants on the local disk though, in the ‘Experiments’ folder (because the network in the lab is not super reliable).
Stimulus materials for VWP experiments
Creating pictures
Pictures need to be in .png format for use in ZEP. Maximum size is the resolution of the participant screen (1440×768 pixels in K.121280×1024 pixels in K.091920×1080 pixels on the SMI laptop).
You can name your pictures using a system that makes sense to you, but be aware that the naming convention for pictures in the analysis phase in Fixation is ConditionNameItemNumber, with the condition name spanning maximally five letters, and the item number spanning exactly three digits. Example: conda001.bmp, condb001.bmp, etc. (ZEP will generate the pictures for analysis for you, see step 5.1 below).
As a general note, please make sure to never use spaces in file names; spaces in file names are supported in only a limited set of environments, and invariably lead to problems at some point in other applications. It is best to avoid them no matter what. In addition, note that some of the programs you are going to use are case-sensitive. So to be on the safe side: use lower case letters only.
By default, the boilerplate experiment displays fairly small pictures. To change the size that is displayed, modify the module test_page.zm. Look for CanvasGadget and change its size.
Creating sound files
The easiest way is to record all your stimuli in a few large files and cut them up into individual files for each trial. Instructions for recording sound files in the phonetics lab are here. Make sure to record in 48000 Hz, and double-check that it sounds OK on the Stimulus PC in K.12K.09the SMI laptop.
It is vitally important to make sure that all your trials sound about the same in terms of volume etc. The only reliable way to control this is to record all your stimuli in one session (mix up conditions if you can, to avoid conditions being identifiable to the participants by their tone of voice), and make sure the speaker doesn’t move much and stays in the same mood throughout.
To cut your sentences into separate sound files, you can use Praat. Praat is installed on all lab PCs, including the PCs in K.06, both under Linux and under Windows. Some useful Praat scripts are available on the General Repository page, here. This .zip file contains:
- read_all_files_in_dir.praat: a Praat script to read all files in a particular directory in to Praat (the regular interface only allows selection of one file at a time)
- findonset.praat: Praat script for skipping to the next sound (useful in a file with long silences)
- insert_silence.praat: Praat script to insert a fixed amount of silence into all sound files in a particular directory. (See below).
- Silence.wav: 1000 ms of silence, see below.
Some hints:
- To open a long sound file, use Read -> Open long sound file. Select the file in the ‘Praat objects’ window, and click ‘Edit’. A new window with a waveform representation will open, that will allow you to cut out the sentences.
- To cut out a sentence, select it in the waveform representation (you can listen to the selection by pressing the corresponding part of the bar at the bottom), and save the selection (File -> Write sound selection to WAV file).
- Save your sentences under a name that makes sense (condition and item number, for instance). Make sure there are no spaces in your filenames!
- If you have very long silences in your recording, you can look for the onset of the next sentence using the ‘find_onset’ script. (Otherwise it’s not particularly useful, easier and more accurate to find and clip the sentences by hand).
- Praat can open only one sound file at a time with Read -> open. To open all files in a given directory in Praat, use the script read_all_files_in_dir.praat. (Praat -> new praat script, File -> open. Ctrl-r to run script).
You will want to add some silence at the beginning of your sound (.wav) files, to allow the participants to scan the picture before they hear the sentence. Do this as follows:
- Open silence.wav (1000ms)
- Modify silence.wav to your needs (longer/shorter). Use ‘select’ to select precise amounts of ms, cut/paste. Save as silence.wav.
- Keep silence open in object window. Open and run Praat script insert_silence.praat. The script will concatenate silence.wav with all the files in your source directory, and output them to the target directory. You can modify the location of your source and target dir in the dialogue box that pops up when you run the script.
- Check that the new files are OK (use script read_all_files_in_dir.praat to open all files and click edit to check them).
- Don’t throw away your original closely-cut sound files, as you may want to change the amount of silence added after running your pilot!
Implement your experiment
Start your experiment implementation on the SMI laptopthe Stimulus PC in K.12the Stimulus PC in K.09, logged in under Linux. Once you have figured out the technical issues, you can finalize your implementation elsewhere.
If you’re not a regular Linux user…
… you may experience some confusion because things work a little differently than you may be used to. For a short primer on Linux commands and conventions, see Working with Linux. Very useful!
Download a boilerplate experiment
The boilerplate experiment for an eye-tracking reading experiment can be found
here. To get started, download the boilerplate experiment
ZEP2-Text-Reading-Eye-Tracking-BOILERPLATE-main.zip to your project folder or to the local ‘Experiments’ folder, and unzip it there.
The boilerplate visual-world experiment is located
here. To get started, download it to your project folder or to the local ‘Experiments’ folder, and unzip it there.
Make up a three-letter name for your experiment. (Note: in the analysis program Fixation, only the first three letters of your experiment name will survive.) Rename the experiment directory and your ZEP script with your three-letter name:
- experiment directory ZEP2-Text-Reading-Eye-Tracking-BOILERPLATE-main rename to YOURTHREELETTEREXPERIMENTNAME
- experiment script reading.zp rename to YOURTHREELETTEREXPERIMENTNAME.zp
- experiment directory ZEP2-Single-Image-Visual-World-BOILERPLATE-main rename to YOURTHREELETTEREXPERIMENTNAME
- experiment script visworld1.zp rename to YOURTHREELETTEREXPERIMENTNAME.zp
Selecting the eye tracker and eyetracking data output format
The experiment is by default configured for use with the EyeLink eye tracker. If you want to use the SMI eye tracker, you have to make some small changes to one source file, /YOURTHREELETTEREXPERIMENTNAME/test/task.zmYOURTHREELETTEREXPERIMENTNAME.zp. Open the file in a proper text editor (such as gedit, Nedit, Notepad++, TextPad – but NOT Microsoft Word or LibreOffice!) and look for the line import eyetracker_eyelink;. Comment the line out by starting it with two slashes //. This makes ZEP ignore that line. Once done, uncomment the line that says //import eyetracker_smi; by removing the slashes. Voila, now the experiment is ready for the SMI eye tracker.
Then, open the module eyetracker_smi.zm with a text editor, and make sure that the eyetracking data is output in the .asc format: that is, check that the following line is not commented out:
data_file_format = EYE_FILE_FORMAT_EYELINK_ASC;
Do a test run of the boilerplate experiment
To get a feeling for how the experiment looks and works, do the following:
Under Linux
Log in under the Linux Operating System on the Stimulus PC in the lab, or on a computer in K.06. To start your experiment in ZEP, double-click the file linux-terminal.sh in your experiment directory. A message pops up: “Do you want to run “linux-terminal.sh”, or display its contents?”. Click “Run in terminal”.
In the terminal that pops up, type zep YOURTHREELETTEREXPERIMENTNAME.zpEnter.
Under Windows
Under Windows, double-click the file windows-terminal.bat in your experiment directory. In the DOS console that opens, type zep YOURTHREELETTEREXPERIMENTNAME.zpEnter.
In the ZEP control window that opens next, click the Start button to start the experiment. Follow the directions on the screen to continue.
If you want to try out the experiment without an eye tracker, choose the simulated eye-tracker. The mouse cursor will then simulate a gaze, and you can use it to get through the drift check (just hold the mouse/gaze over the drift check dot). If this doesn’t work, you can use the space bar to get through the drift check.
To abort ZEP at any time: press alt-F4 (prompts for confirmation) or ctrl-break (no confirmation).
Responses and timing
All these boilerplate experiments can accept a response from the participant, either through the button box, keyboard or mouse. The response time is measured from the onset of your auditory stimulus.
By default, the experiment moves on to the next stimulus when the participant gives a response, or at the end of the sound file (if no response is given).
You can make it impossible for the participant to give a response until a certain amount of time has passed: in the file test/defs.zm, set the variable RESPONSE_SHIFT (by default this variable is set to 100ms before onset of the sound file).
Create your own stimulus file
Specify your stimuli in /YOURTHREELETTEREXPERIMENTNAME/stimuli/test_items.csv.
It may be helpful to consult this page about working with .csv files.
In the .csv file in the boilerplate experiment, each row beyond the header describes one trial (including a question, which is optional). The meaning of the columns is:
- index This column determines in which list a stimulus will appear. If you have eg. four lists this column will have four indices. Indices start at zero, hence there will be a number of 0, 1, 2 or 3’s in this column. Stimuli with index 0 will appear in the first list, indices 2 in the third etc. NB1: ZEP uses the participant’s group number to control which list the participant sees. A participant with GRP1 will get list 0, a participant with GRP2 will get list 1, etc. Specify the names for your groups in the file YOURTHREELETTEREXPERIMENTNAME/modules/grouping.zm. NB2: The .csv file for the practice items doesn’t have this index, as the stimuli in the practice block are displayed in the order specified in the .csv file (no pseudorandomization).
- id This is the item number of the trial. Use three digits for the item numbers (001, 002 etc). Excel/OpenOffice/LibreOffice will ‘helpfully’ try to delete the leading zeros in your item numbers (it will change ‘001’ to ‘1’); to prevent this, format the column as text. (The item number needs to have three positions for the data processing in the analysis phase.) Of course, make sure that the combination of item number and condition is unique for all items.
- type This column refers to the experimental condition of the stimulus. The entered value has to correspond to the values in the /YOURTHREELETTEREXPERIMENTNAME/test/stimuli.zm file (note that it is case senstive). Specifically they should match one of the values in the enum ItemType. In the boilerplate experiments, the conditions are PRAC, FILL, CNDA, CNDB, CNDC, CNDD – which map to practice, filler, condition A, B, C and D respectively. Make sure to rename the conditions to names that make sense to you, so that you’ll know what each condition is in the analysis phase. Remember: use NO numbers, and use five letters maximum(four if you measure eye movements on question pages, as question pages will be prefixed with a Q thus taking up one letter space)!
- image_filename Specifies the file name for the visual stimulus.
- sound_filename Specifies the file name for the auditory stimulus.
- expected_answer Set this variable to true if the expected answer to the question is correct, false otherwise.
- record_eye_movements Set to true if the eyetracker should record the eye movements in this item, false otherwise. Set to true for all experimental items, false for fillers.
- do_drift_check Set to true if the trial should be started with a drift check, false otherwise. Is usually set to true.
- text Here the text for the stimulus is written (see Stimulus formatting below).
- driftchk Set to true if the trial should be started with a drift check, false otherwise. Is usually set to true.
- receye Set to true when the eye movements should be recorded for the text. Set to true for experimental items, false for fillers.
- qtext The question that belongs to this trial.
- qdriftcheck Set to true when the question should be preceded with a drift check, false if not. You will usually set this to false for all trials (unless you are measuring eye movements on the questions, of course).
- qreceye Set to true when the eye movements should be recorded for the question.
- qanswer Set this variable to true if the expected answer to the question is correct, false otherwise.
Stimulus formatting:
- Make sure the critical region in your items is not at the beginning or end of a line. It is advisable to start out with a small stimulus file with only a couple of stimuli, where you can fiddle with linebreaks and font size. It is best to do this on the Stimulus PC in K.12the Stimulus PC in K.09 – while you can run ZEP in room K.06 or at home as well, it won’t give you an accurate idea of linebreaks, as the screen resolution on the PCs there will be higher. If you do work at home or elsewhere, change the screen resolution to 1440×10801280×1024, and remember that fonts that are available on your computer, may not be available in the lab. Using a monospaced font will be the best for most cases.
- Start out with the item that is most likely to be problematic (for instance, the item where the critical region has the most characters).
- You can use a spreadsheet program (Excel, LibreOffice, OpenOffice) to create your stimulus file. The benefit of using Excel/LibreOffice/OpenOffice is that it allows you to keep a better overview of your file if your stimuli span multiple lines. The disadvantage, though, is that these spreadsheet programs will try to be smart in ways that tend to mess up your stimulus file to a point where ZEP can’t read it any more. In practice it is best to start out in a spreadsheet program, and do all the fine tuning in a proper text editor. Some notes on using spreadsheet programs:
- Excel/LibreOffice/OpenOffice will give you a dialog box about the text import when you open the stimulus file from the template experiment. In this dialog box, make sure that the character set/encoding is UTF8, that you UNcheck ‘space’ as the separator (the separator between fields is the semicolon ‘;’), and that under other options you UNcheck ‘quoted field as text’. It is best to try to import every column in a string format. If you don’t do this, the spreadsheet will try to outsmart you, whether you want or not. Typically, this is demonstrated when importing the string (a number of characters) “001”, the spreadsheet will interpret that as a number and when you save it it will be “1” ommitting to the 2 “0” characters. You can inhibit this when importing the columns as strings, this is at least possible with LibreOffice.
- In the spreadsheet programs you can use alt-enter or ctrl-enter (depending on your platform) to input a line break within a cell.
- Save as text (.csv)
- Test that your production line works OK by putting in just one stimulus into the template .csv file, and seeing if it works. If ZEP gives you the error ‘unable to load “stimuli/test_items.csv’, that means something is wrong with the format of your stimulus file. Make sure that the file is in UTF-8 and has unix linebreaks (Notepad++: View -> Show Symbol -> Show end of line should show only LF, not CR characters; to change, replace \r\n with \n in extended mode). Check in a text editor whether the spreadsheet program has decided to ‘helpfully’ insert quotes where you don’t want them. If you don’t see what’s wrong with the file when you look at it in a text editor, ask Iris for help.
- Once you are happy with the general format for linebreaks and the fontsize, add the rest of your stimuli.
Markup, like bold and italic:
- You can use html-style tags, like <b> …</b> and <i> … </i> to create bold or italic markup in your stimuli.
- A problem with using markup, is that your .obt files that ‘know’ where all your words are on the page (see step 5.1 below), will come out wrong, because the tags will be assumed to take up space that they actually don’t. Confer with lab support for the best solution in your particular case.
Fonts, font size and spacing:
- For a first approximation of your stimulus layout, work on a computer with a resolution that is similar to (the participant monitor of) the computer you will be running the actual experiment on: 1440X1080 pixels in K.121280×1024 in K.091920×1080 pixels on the SMI laptop.
- The font size of your stimuli can be changed as follows. Find the file fonts.zm in your modules directory, and modify TEST_PAGE_STIMULUS_FONT_SIZE.
- To find out which TrueType fonts are available on your system, run zeplistfonts in the console.
- If you need to use a font that is not available in the lab: you can install a TrueType font in ~/.fonts.
- If your stimuli consist of more than one line, you will need to adjust line spacing – the boilerplate script used to put the lines too close together. In longer texts it is very important to have sufficient spacing between your lines, otherwise assignment of the fixations to lines in the data cleanup phase is impossible to do. It should look like you can almost put an entire line in between the lines, and the more space between the lines, the easier data cleanup will be. The boilerplate experiment chooses this setting automatically.
- If you are running your experiment in Chinese (or any other ideogrammatic script), you will need to separate all your characters by a space. See step 5.1 below for the reason.
- To adjust line spacing or letter spacing: in the test_page.zm file you’ll find a line containing
line_spacing = line_height * 1;. This controls the number of pixels between lines. Since the line_height is multiplied by 1, you end up with a spacing identical to line_height, so if you want to be able to put one and a half line in between, you would multiply with 1.5. Similarly you have “letter_spacing” which controls the number of pixels (tenths of a pixel actually) between characters. You can play with the spacing using the lettersp.zp script. Keys:
esc -> quit
arrows -> adjust spacing
F1 -> reset letter spacing
F2 -> reset line spacing
Of course you can also just adjust the spacing in your experiment script and evaluate it by running the experiment.
- Play around until it looks good to you and then ask Iris to look at it.
- If you want to record eye movements on the questions, apply exactly identical font and spacing settings to the module that formats the questions: question_page.zm.
Specify your practise items in stimuli/prac_items.csv.
Specify the pseudo-randomization of your items
Out of the box, the boilerplate experiment will present your experimental stimuli in a different pseudo-randomized order for each participant. The pseudo-randomization follows the constraints specified in /test/shuffle.zm. In the boilerplate experiment the following constraints are specified: no more than three experimental items may appear in a row, no more than two experimental items in the same condition may follow each other, and the first trial must always be a filler.
You can adapt the constraints in /test/shuffle.zm to your own needs. If you need help to implement your ordering constraints, ask Maarten Duijndam.
You can preview the kinds of orders that are generated by setting the variable DUMP_TEST_ITEMS in defs.zm to true and then running your experiment. This will output a possible order for your current list, in the terminal.
You can preview the kinds of orders that are generated by running the test program zep test_pseudorandomisation.zp. This will output a possible order for all the lists in the terminal.
Your practise items will always simply be displayed in the order you specify in stimuli/prac_items.csv.
No pseudo-randomization
If you want to present your experimental stimuli in a fixed order, you will need to edit the task module test/task.zm. Find the lines
if (shuffle_test_items(selected_group) != OK)
terminate;
and comment them out. That is, put two slashes before the line, like this:
// if (shuffle_test_items(selected_group) != OK)
// terminate;
If you want to present your experimental stimuli in a fixed order, you will need to edit the module session.zm. Find the lines
if(test::shuffle_stimuli(selected_group) == ERROR)
return ERROR;
and comment them out. That is, put two slashes before the lines, like this:
// if(test::shuffle_stimuli(selected_group) == ERROR)
// return ERROR;
Now specify the stimuli in the desired order in the /stimuli/test_items.csv file and make sure they have the right list number. So if your .csv file looks something like this:
index;id;type;
0;001;FILL;...
1;001;FILL;...
2;001;FILL;...
3;001;FILL;...
0;001;CNDA;...
1;001;CNDB;...
2;001;CNDC;...
3;001;CNDD;...
etc
Participants in group GRP1 will then always get FILL001 and CNDA001 in that order, group GRP2 will get FILL001 and CNDB001 in that order, etc.
Instruction texts for the participant
In the boilerplate experiment, instruction texts are written in English. You will want to adapt these texts for your experiment. To do so, open task.zm in the folder test with a text editor.
Language of the buttons
You can set the language for the texts of the buttons, the welcome screen, etc, by importing the appropriate module (language modules are for instance std_texts_cn.zm for Chinese, std_texts_nl.zm for Dutch). To see how to import a module, open your YOURTHREELETTEREXPERIMENTNAME.zp script file with a text editor, and search for import to see how it’s done.
If you want to change anything in a language module (for instance, change yes/no as answer options to correct/incorrect), copy the module from the module directory of the ZEP installation directory to the module directory of your own experiment and make the changes in that copy. In the lab under Linux the ZEP module directory is usr/share/zep/2.6/modulesIn the lab setups under Windows the ZEP module directory is C:\Program Files (x86)\zep\1.14\modules; if you are working on your own PC, it depends on where you installed ZEP of course, and which version of zep you are using.
If all this is confusing to you, ask a technician in room 0.09 for help.
Preparing/finishing stimulus files under Windows
You can finish preparing your stimulus file outside the lab, to free up the lab for running actual experiments. You can work in the terminal room (K.06) under Linux; or at home or on your work PC, using the Windows version of ZEP (for downloads and documentation see
the ZEP homepage).
Here are some known issues with preparing stimulus files under Windows:
- DO NOT use Microsoft Word or Wordpad to prepare your files; use a proper text editor instead, such as Notepad, Notepad++, or TextPad.
- Your files need to have DOS/Windows line breaks, and the character encoding has to be UTF-8.
- TextPad gives you usable files if you save them using File -> Save as -> File format: PC, and Encoding: UTF-8.
- To set the default encoding in Notepad++: go to Settings -> Preferences -> New Document/Default Directory, and select UTF-8 as the encoding, and ‘Windows’ as the Format. To fix a wrongly encoded file, go to Encoding -> Ansi and save.
- Notepad will give you useable files if you use ‘save as’ and specify UTF-8 as the font encoding.
For preparing stimulus .csv files, you can also use Excel, OpenOffice, or LibreOffice Calc under Windows, but this is usually an extremely frustrating endeavor, as explained above, and in this page about working with .csv files. Better to work in a text editor, especially if your stimulus file is nearing completion.
Back to Step 1. Before you start
Up to steps overview
Step 3. Test your experiment in K.12in K.09on the SMI laptop
Check the illuminator and lens
The large rectangular panel beside the camera is the infrared light source/illuminator; we have two illuminators which correspond to two different sets of wavelengths used:
- In infants under about 9 months, the eye is not fully developed and it reflects differently than the adult eye. Therefore the 940 nm illuminator is used for infants under 9 months, and the 16mm lens with the lock screw at 2.0 (using this lens is not critical, but may help – it has a smaller range in which you can focus than the lens for older children/adults).
- For children older than nine months and for adults, use the 890 nm illuminator. With this illuminator, we use a 16mm lens that has a wider focus range.
You can identify the illuminator by a label that is stuck on the side – it will have 890 or 940 somewhere in the mode number. If necessary, use an allen key/wrench to exchange the illuminator and be sure to plug the power cables from the illuminator into the camera block. The 16mm lens to use with infants under 9 months old has a locking screw and index line aligned underneath the 2.0 setting printed on the lens (IRIS wide open). Ask for help from Maarten Duijndam or Iris Mulders if you are unsure.
Switch on the equipment
- Switch on the SMI laptop. Always keep it on the charger to avoid running out of power mid-experiment.
- The laptop will boot in Windows 8, you don’t need to log in.
- Click the eyetracker on to the laptop. Make sure you hear the magnetic thingy ‘click’ into place. Make sure you use it right side up (cord on the right side of the eyetracker).
- Plug the USB eyetracker in in the port labeled ‘RED’ (the cord crosses over to the USB port behind the screen).
- When the LED lights come on in the eyetracker, it’s working.
Now start the SMI tracker software. This software needs to run in the background for the eyetracker to work.
- Press the Windows button to get to the Windows-8 tile menu.
- Double-click iVNGRED Server. The software will start and the icon will appear in the services taskbar.
In order to avoid possible damage as a result of power surges, the most sensitive equipment should be powered up last. The order in which the equipment should be powered on is:
- Monitors: participant monitor in the booth, Stimulus PC monitor and EyeLink Host PC monitor in the control room.
- Stimulus PC; by default, the Stimulus PC will boot up in the Linux Operating System.
- EyeLink camera: to switch on the camera, switch on the power strip in the booth, on the table behind the participant monitor.
- EyeLink Host PC: the EyeLink Host PC boots into DOS and starts up the EyeLink software by default.
Always shut down in reverse order (see below at the end of Step 6).
- The power strip that controls the power for all the equipment in the control room. It is located under the table that holds the EyeLink Host PC monitor.
- Button box: if your experiment uses a button box, make sure the USB cable of the button box inside the participant room is connected; also make sure that the USB cable is unplugged from the button box in the experimenter room (this button box is used in some infant experiments). You can just plug/unplug the cables at the button box itself, no need to mess with where they are connected in the PC!
- Stimulus PC; by default, the Stimulus PC will boot up in the Linux Operating System. Wait until this process is finished.
- EyeLink Host PC and Stimulus PC monitors. Switching on the Stimulus PC monitor in the participant booth will also switch on the EyeLink camera. (This is a nifty feature of the master-slave power strip in the participant room, which is on the floor hidden behind the curtain – you won’t need to touch this power strip at all.) NB: if the monitor is sleeping the camera won’t switch on, but it should come on as soon as you have an image on the monitor.
- EyeLink Host PC: the EyeLink Host PC boots into DOS and starts up the EyeLink software by default.
Always shut down in reverse order (see below).
Monitors
By default, the monitor inside the participant booth is set up as an extension of the experimenter monitor outside the booth, in the control room. This allows you to see information about the progress of the experiment on the experimenter monitor.
This setup means that the monitor inside the participant booth shows a fairly empty screen with no icons. If the participant monitor looks exactly like the experiment monitor, they are set in clone mode, and that is not what you want. To fix this, choose System tools -> Display in extended mode to set up the participant monitor as an extension of the experimenter monitor.
This does mean that you have to start your experiment in the control room, and move inside the booth/participant room to see your experiment run.
We have a small external USB screen that can function as an experimenter monitor, to allow you to follow the participant’s gaze during the experiment, so that you can correct their position during the experiment if necessary. Connect it on the left side of the laptop (as the primary screen, laptop screen should be secondary). If necessary, you can plug in the extra, short USB cable from the external monitor for extra power.
Press F9 to make sure that the ZEP control window appears on the external screen, and the test window on the laptop screen. Do not drag windows around with the mouse to make them appear on the correct screen; if you do that you will run into problems when creating the screenshots in step 5.1 below.
During the experiment, you can press F5 to see the stimulus together with the participant gaze, in the ZEP control window on the experimenter monitor.
Back to Step 2. Prepare your experiment
Up to steps overview
Step 4. Calibration
This section outlines how to perform camera setup and calibration in the context of our lab.
The full setup procedure for the EyeLink Remote can be found in the
EyeLink 1000 User Manual, section 3.2.4, pp.55-61, and sections 3.7 and 3.8, pp.69-74. The EyeLink 1000 User Manual is also available in hard copy in room K.12.
Working with the equipment does require some instruction and practice; please read the information in this section, and contact Maarten Duijndam or Iris Mulders for a tutorial.
Starting the experiment software
- Start your experiment in ZEP.
- NB: if you have been moving your experiment between Windows and Linux, it may happen that the executable bit on the file linux-terminal.sh is lost, in which case the system will simply open the file in a text editor instead of offering to run it in the terminal. If that happens, right-click the linux-terminal.sh file in the window manager, go to ‘Properties’, ‘Permissions’, and check the box ‘Is executable’:
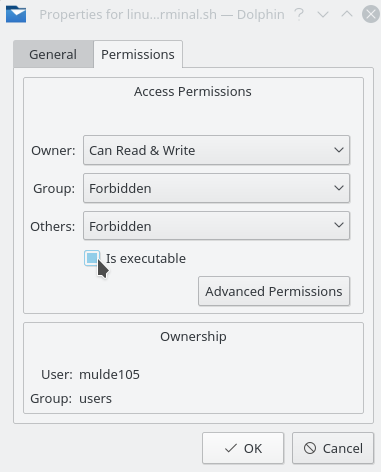 Then try again.
Then try again.
- Press the ‘Experiment’ button and change the experiment status to ‘piloting’ or ‘testing’, depending.
- Create a participant and select it. The participant ID has to have the format ‘pp###’, for instance pp001, pp002 etc. (Do use exactly this format, otherwise you’ll run into problems when you have to convert your data later on in the process).
- Press ‘Start’ to start the experiment. At the Welcome screen, press the space bar to advance to the next screen.
- You will get to a screen with the following options:
 |
| ZEP Connect to Eyetracker Menu |
- Press L to connect to the SMI eyetracker. A box will appear on the screen with a representation of the eyes. (Drag this to the external left screen if you are using it).
- You will get to a screen with the following options:
 |
| ZEP Connect to Eyetracker Menu |
- Press C to connect to the EyeLink eyetracker.
- Follow the instructions on the screen, until you see a screen that looks like this:
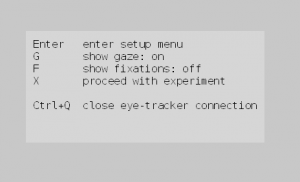 |
| ZEP Eye-tracking Menu |
- Press Enter to go to the ZEP camera setup menu.
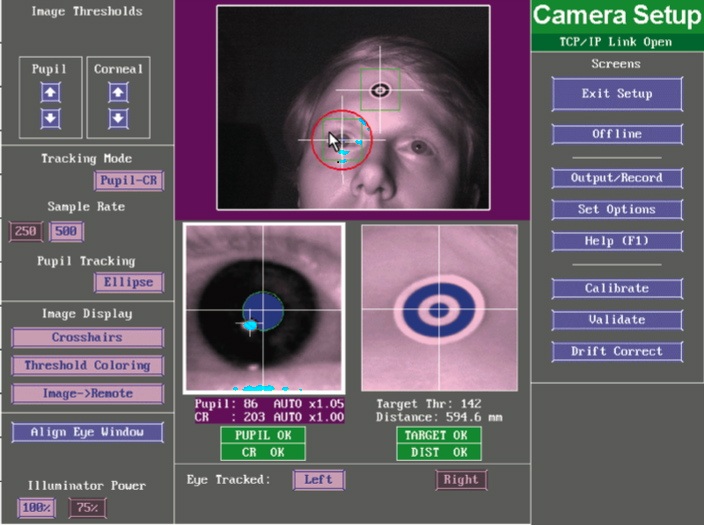
Camera setup and calibration
When your experiment script opens the connection to the EyeLink Host PC, you will see the following screen appear on the EyeLink Host PC:
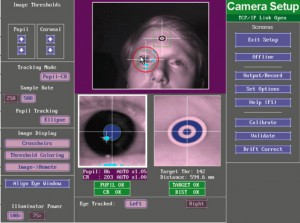 |
| EL1000 setup screen |
This screen gives an overview of the options that are available to you at this point (setting up the camera image, calibrating, validating etc.).
In principle you can operate the software from the EyeLink Host PC keyboard by either clicking on the function you need with the mouse, or by using the corresponding keyboard shortcuts (for instance, press c to enter the calibration routine). However, when you are running an experiment using ZEP or any other experiment program, it is advisable to control the communication with the eye tracker through the experiment program, using either the Stimulus PC keyboard in the control room, or in the participant room. The commands that are not implemented (such as pupil threshold adjustment) can be done with the mouse directly to the EyeLink Host PC, but things like starting calibrations are best done through the experiment/display software, to prevent miscommunications between the EyeLink Host PC software and ZEP.
When the ZEP script reaches the camera setup part, on the Display monitor in the booth you will just see the ZEP camera setup screen.
The ZEP camera setup screen indicates the keys corresponding to the menu options that are available to you at this point:
- Enter will take you to the views of the camera image
- c will take you to the calibration screen
- v will take you to the validation screen
- d will perform a drift check (you won’t need to manually invoke this option)
- Esc will take you out of the camera setup menu, back up to the eye-tracking menu
To start the setup procedure, press Enter to see one of the camera views (head view, eye close-up, target sticker close-up). Pressing the left or right cursor key will switch between camera views. Press one of these cursor keys to switch to the head view.
Place a target sticker on the participant’s forehead, somewhat off to the right (see image above). Adjust the height of the participant chair so that the participant’s eyes are level with the top half of the monitor. The seat can be moved up by pumping the foot pedal, and down by stepping on the pedal (push through). If necessary you can slightly tilt the camera mount to make the eye appear vertically in the middle of the overview camera image, or adjust the book stack under it to move it up/down. Push the chair close to the table to get about the right distance to the screen.
The system should now find the right eye and the target sticker automatically. A white cross will be drawn through both, and a green circle and a red box will appear around the right eye, and a green box around the target sticker. Focus the camera by turning the lens.
The participant should be positioned at about 600mm from the camera (anywhere between 550 and 650mm should work, but aim for 600mm as the optimal distance so that participants still have some room to move). Go to the control room and check the ‘DIST’ status message below the camera image on the EyeLink Host PC to see what the distance is.
Use the EyeLink Host PC mouse to click on the pupil of the participant in the overview camera image. This will line up the search boxes, and set the threshold for the pupil and corneal reflection. You’re looking to get an image where the pupil appears a solid dark blue with a green line drawn around it, and the CR (corneal reflection) in turquoise. Make the participant look at the corners of the screen to ensure you have a good image in all positions.
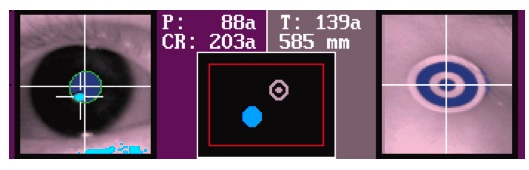 |
| EL1000 eye image |
When you have an acceptable image of the eye, press Esc to return to the menu, and c to open the calibration routine. The calibration routine consists of the timed presentation of thirteen points on the screen. Instruct the participant to look at the dot that appears in the middle of the screen, and press Enter; the thirteen calibration points will be presented on the screen in random order.
If there are problems with the camera setup, nothing will happen when you press Enter, or the system will seem to ‘get stuck’ at the presentation of a calibration point. If this happens, the EyeLink Host PC screen will probably tell you that the pupil is missing. In this case, press Esc to return to camera setup, and make adjustments there.
Things to check for in case of problems (in decreasing order of likelihood):
- Make sure the participant’s hair is not obscuring the target sticker. (Use our assortment of hair clips and headbands to keep the hair off the forehead).
- Check that the target sticker is not too close or too far away from the eye; if it is, EYEDIST will appear in red (see EyeLink User Manual).
- ANGLE error message: indicates that the target sticker is seen from too large an angle by the system. Check that the target sticker is not too far off to the side of the participant’s forehead, or too high up, in case the participant’s forehead slopes backwards. In the latter case, try to move the sticker closer to the eye then. (But not too close, if it’s too close you’ll get an EYEDIST error).
- Check the distance to the monitor. (DIST)
- You may need to turn down the lights. (The booth light switch has a dimmer; always close the booth door for calibration to get rid of disturbing lighting from the control room).
- If you see that one calibration point lies far outside the grid, this is usually caused by the camera being too far off to the side of the screen; if the camera films the eye from the side, a shadow will appear on one side of the iris that the system may confuse for part of the pupil in some angles. Usually the best image is obtained by having the camera straight in the middle of the monitor, and the participant’s face in the middle of the camera image.
- Another cause of one calibration point lying far outside the grid is the appearance of an extra corneal reflection in a certain position; you may see the crosshair for the CR reflection ‘jump’ (due to another CR reflection popping up in certain positions). Moving the participant a bit further away from the screen (no further than 700mm) usually helps. Setting the CR threshold value a bit lower may also help (click the arrows in the top left of the EyeLink control screen. You can also press the + or - key to control the CR threshold, but this does not always work during an experiment).
- The pupil threshold bias may be too high or too low. To adjust the threshold, click the arrows in the top left of the EyeLink control screen. You can also press the up or down arrow keys on the keyboard to adjust, but this does not always work during an experiment. Make sure you have a good solid image of the pupil, and that the pupil image doesn’t ‘merge’ with eyelashes or other dark parts of the image. Mascara may (but usually does not) interfere with the system finding the pupil. NB: adjusting the threshold manually is usually not necessary, and once you have adjusted the threshold manually, it can take about 30 seconds for the threshold adjustment to switch back to automatic.
- If the right eye is giving problems, you can try to measure the left eye instead: go to the EyeLink Host PC, and select which eye to measure by pressing E (toggles between left and right). Make sure to move the target sticker to a position over the left eye. If you do change over to measuring the left eye, don’t forget to change the setting back to the right eye for the next participant!
If the participant is wearing glasses:
- Adjust the infrared illumination level from 75% to 100%.
- Move the participant closer to the screen: distance around 550-600 mm. But not too close, because too close a distance may result in large drift during validation.
- Make sure the face of participant is straight in front of the camera. When the participant is wearing glasses, Eyelink data quality may be very sensitive to even slight angles between the face and the camera.
- If the reflection on the glasses is obscuring the pupil, or competing for the corneal reflection, you can try the following:
- Measure the other eye. Toggle which eye is measured by pressing E in camera setup.
- Instruct the participant to keep the chin up, then the extra reflection point is excluded from the search box. Again, the chin should not be moved up too much, because the system may report “Angle” on the target, which may effect data quality.
- If you get reflections competing with the corneal reflection, you can adjust the size of the search limit box by pressing alt-arrow keys; its position can be adjusted with shift-arrow keys (these operations can only be performed from the EyeLink Host PC keyboard).
Once you have a stable image of the pupil, return to the calibration by pressing c.
Instruct the participant: during calibration the participant should fixate each point until it disappears, and keep her head as still as possible.
While the participant is doing the calibration, look at the image of her eye at the bottom left of the EyeLink Host PC screen, and check for the following aspects:
- Watch the pupil and the CR reflection to make sure they are solid at all angles and no unwanted competitors pop up.
- Make sure that the pupil and the target sticker stay neatly in the red box at the bottom of the screen.
- Check that the participant doesn’t look away too quickly from the calibration points.
You won’t have enough eyes to check for all these things at the same time; feel free to repeat the calibration procedure a few times.
Make sure to warn the participant if they move their eyes away from the target too quickly. Most first-time participants will want to look away too quickly and need to be explicitly trained to not do this; it is natural to want to look away as soon as they have seen the calibration point, but this behavior will mess up your calibration as well as cause the drift checks later to take longer than necessary, so take your time to train them and repeat calibration and validation if necessary after instructing them again. Tell them to just keep staring at the dot until it goes away.
Below are some illustrations of good and poor calibration results:
 Examples of calibration results |
You will have to evaluate the calibration result visually; the system does not evaluate, it will also say that the calibration succeeded when it is not good. In case of less-than-perfect calibration, press Esc, and repeat the procedure.
If the calibration is good, press Enter to store the results, and proceed with the validation routine.
The validation routine is a check on the accuracy of the calibration results. The validation routine is similar to the calibration routine; again, thirteen points are presented randomly on the screen and the participant should fixate them consecutively. Get into the validation routine by pressing v, wait until the participant is looking at the dot in the middle of the screen and press Enter to start.
In case of ‘poor’ or ‘fair’ validation results, press Esc and press v to repeat the procedure. If no valid validation results can be obtained, press Esc and restart the procedure from the beginning, that is, check the participant’s positioning, calibrate, and validate. Remember that each succesful calibration and validation run should be concluded with Enter. Only then will the program store the results.
Keep your cool and take your time getting a good calibration and validation. Taking five minutes of extra time to get this right, will save you a lot of time in the data cleanup phase.
After saving the successful calibration and validation results, leave the setup menu by pressing Esc and then proceed to the experiment by pressing X (i.e. just follow the instructions on the screen).
To get rid of artifacts in the presentation of the calibration dots, lower the resolution of the secondary monitor (ask Iris for help – involves pressing alt-enter and searching for arandr).
Drift check
During the experiment, every trial will be preceded by a drift check. In reading experiments, the drift check calibration point should appear at the position of the first word of the consecutive text. The participant should fixate the drift check point carefully, and again keep looking at it until it disappears and doesn’t reappear again.
Occasionally drift check will fail during the experiment, in particular if the participant looks away from the drift check target too quickly, or if the camera is not set up correctly (see above for instructions on how to do that properly), or if the participant has moved a lot.
If there is a large discrepancy between the drift check point and where the system thinks the participant is looking, the EyeLink Host screen will flicker red and the EyeLink Host PC will beep; ZEP will redisplay the drift check target over and over again to the participant. If this goes on for a long time, you will need to perform a recalibration. You can get into the proper mode to do that as follows: use the EyeLink Host PC mouse to press ‘Eye-tracker setup’ (or ‘Discard’, but NEVER ‘Calibrate’) on the EyeLink Host PC. Alternatively, you can press Esc during the drift check.
You will see the regular Setup screen appear on the Stimulus PC. If necessary, reposition the participant (or camera) as outlined above; participants will sometimes start to slouch during the experiment or otherwise move. Make sure you do the setup in a position they are comfortable in (so don’t tell them to sit up straight, but just move the chair up if they have indeed started to slouch). Perform a new calibration and validation as indicated above: start the calibration by pressing c on the Stimulus PC (NOT the EyeLink Host PC), accept the results with Enter for both), and then press Esc to resume the experiment.
Press Enter to see the camera view. An SMI-specific window pops up; you can ignore that and get back to the ZEP screen by clicking on the ZEP screen.
Now first position the participant so that you get a good view of their eye. Take note of the distance; the range in which the eyetracker can measure is between 60 and 80cm from the eyetracker. Press Esc to get out of camera setup mode and return to the screen above.
Then start a calibration by pressing c followed by Enter. A calibration dot will appear in 13 positions on the screen (for use with young children fewer points will be advisable; you can switch to infant calibration by importing the module eyetracker_smi_infant.zm rather than eyetracker_smi.zm. A 9-point calibration is also possible). Instruct the participant to keep their head as still as possible during the calibration, and to keep looking at each calibration point until it disappears (=not anticipate to where the next point may appear).
The SMI calibration gives visual feedback on the calibration result, specifying the deviation in degrees. Note that if one calibration point went wrong, all points will show deviations. The calibration routine remembers the last calibration you did.
After calibration, start the validation. Validation is just a check on the last calibration, and only four points are presented during validation. (With subjects with a short attention span, like small children, you may skip the validation).
Some participants move around a lot, so much that they move out of the range of the eyetracker. Here are some things you can consider to fix this:
- Use a stable chair: no wheels, no moving parts.
- Consider using a chin rest. We have one in the lab that you can borrow. For added stability, you can tape it to the table with ducttape, if the place you are testing in is cool with that (we are not cool with it in the lab, sorry).
- For younger children, a good position can be to let them kneel on the chair, have them rest their elbows on the table, and rest their chin in their hands. You will need to elevate the laptop to get the screen high enough, for instance put it on top of the flightcase.
If something goes wrong during your experiment
Some known issues; please do still report these issues if they happen to you!
- Sometimes the drift check page does not appear, and instead a blank page appears. Usually you can get out of this blank page by pressing Esc. If Esc doesn’t work, try to press F2 (brings the focus back to the control window) followed by Esc.
- Occasionally, the experiment will seem to ‘freeze’ after the drift check has been completed – it’ll look like the drift check went fine, but the experiment will not move on to the next trial. It’s not entirely clear why this happens. To get out of this frozen state, press Esc and do a recalibration.
- Occasionally the validation will show large offsets for all calibration points. The offset will be very similar for all points, and really large (like 4 degrees). Our currrent idea is that when this happens, the calibration somehow wasn’t saved via the ZEP program as it should be. To fix this, you can redo the calibration, and accept this calibration on the EyeLink host PC by using the mouse (click on ‘accept calibration’). Then it is saved and from our previous experience it won’t happen again so you can continue the normal flow. (Only accept a calibration result on the EyeLink Host PC in this situation! Generally it is not a good idea to operate the EyeLink directly from the EyeLink Host PC as this may confuse ZEP).
- Rare: when there are problems with the university network, ZEP may seem to freeze. If this happens, just waiting it out seems to be the best strategy. To avoid any network problems, run your experiment from the local disk rather than from the network drive.
- Flickering participant monitor: this will happen if the refresh rate is set to 60Hz. Ask lab support to change it back to 85Hz.
- Screen goes black during experiment: probably a display power management issue, the computer switches off the display to save power (when the only input the computer gets is button presses from the button box). The computers should be set up in such a way that this can’t happen, but sometimes stuff happens. Ask lab support to fix it.
- Error ‘Cannot connect to eyetracker’ – sometimes it helps to restart the system (both EyeLink Host PC and Stimulus PC. If it takes a very long time for the Stimulus PC to shut down, you may use the power button to switch it off).
- Disappearing crosshairs and circles: if you lose the green circle around the pupil, but the system is still measuring eye movements, you may be able to get the markings back by pressing ‘Crosshairs’ on the left in the EyeLink screen.
- Rare: the calibration may switch from a 13-point to a 9-point calibration. We don’t know what causes this, if you encounter this, please let us know.
- Extremely rare: the camera image may display in reverse (such that right is left and vice versa). Solution: quit the EyeLink software and restart it (type elcl at the prompt and press Enter).
- There used to be a known bug in ZEP that sometimes causes the calibration screen to be superposed over a trial that no eye movements are being measured on (a filler item). We think we’ve fixed this. If you encounter it anyway, please let us know!
- There used to be a known bug in the Linux graphical interface, that occasionally caused the whole operating system to shut down and return you to the login screen. In the eye-tracking experiments, this mostly seemed to happen at the transition between the practice block and the first test block, so no actual data was lost. We think this should be fixed in the Kubuntu version that we are running now, if you encounter it anyway, please let us know!
- Sometimes the SMI will lose the eyes completely. If that happens, try things like close and start up ZEP again, restart the iVNGRED Server, restart the whole computer, disconnect and reconnect the eyetracker.
- If the SMI is on for more than a few hours, it will give you only zeros as data points (so essentially it will stop measuring). The only known fix is to restart the iVNGRED Server. Right-click the icon in the serivices taskbar and restart it from there. Make sure to do this before every participant, to be on the safe side.
What to do if the experiment crashes/does extremely strange unexpected things, or if the operating system freezes/crashes:
- Let the participant know that there’s a technical problem. Don’t panic – the worst thing that can happen is that you’ll end up with no data for this participant, which is a pity but not the end of the world.
- Note in your experiment log at which trial the problem occurred. You can read off the trial item number and condition from the status line on the EyeLink Host PC (bottom of the screen), or off the ZEP control window.
- Decide on a course of action. If you’re still at the start of the experiment and the participant hasn’t seen any experimental trials yet, you’ll want to keep the participant there and restart the experiment. If the problem occurs further on in the experiment, the best course of action probably is to send the participant home (do pay/reward them and apologize as it’s not their fault).
- Copy the ZEP output that you see in the terminal, to a file and save it. It may contain important information for lab support to prevent the problem from occurring in the future.
- Restart the experiment if you want to, using the same participant number etc; the old data will not be overwritten because the new session will be saved to a new file.
- If ZEP wasn’t shut down properly, you will get a message that the database is locked. To unlock the database: make sure ZEP is not running, and run zepdb2check -fix in the terminal. See the ZEP manual for more information.
- If you can’t get ZEP to shut down at all, try to kill ZEP from the command line (you might need to open a new terminal): pkill zep. If that doesn’t work either, try pkill -9 zep.
- Please let lab support know what happened: go to room 0.09 on the first floor, or alert the support staff by email or phone. Be as specific as you can about what you were doing at the time of the crash.
- The .edf file from the failed run of the experiment will not be transferred to the Stimulus PC, since the transfer happens only at the end of the experiment. If you were almost at the end of the experiment, you may want to retrieve the .edf file for analysis, if so, ask lab support for help to do that, on the same day (note for support: this may involve running zepgetedf sessionnumber_blocknr, edfinfo).
- It is also possible to manually retrieve the .edf file from the EyeLink Host PC by browsing the EDF directory in DOS or Windows 7 and copying the desired files to a USB drive.
- Ask lab support to run chkdsk on the EyeLink Host PC (to check the EyeLink Host PC for lost clusters etc).
Back to Step 3. Test your experiment in K.12in K.09on the SMI laptop
Up to steps overview
Step 5. Pilot and prepare for subjects
5.1 Generate helper files that you’ll need to read your data in in Fixation
To analyze your data in Fixation, you will need to generate .bmp screendumps of your stimuli:
- Start the experiment as follows: zep YOURTHREELETTEREXPERIMENTNAME.zp --generate. Just start the experiment in preparing mode. This will skip the calibration etc and make all screenshots for all your lists in one go.
- Still make sure you do this on the machine you will use for testing with the same resolution as you will do when testing.
- Make sure all screenshots are made.
- Stay in the terminal and go to the data directory by typing cd data.
- Still in the terminal, now run mkobtzep.py YOURTHREELETTEREXPERIMENTNAME 1. This runs the Python script mkobtzep.py for your experiment for list 1 – change the number and run it again to run mkobtzep.py for all your other lists (mkobtzep.py YOURTHREELETTEREXPERIMENTNAME 2 etcetera). This converts your .png screendumps to .bmp. It also generates .obt files that you will need in the analysis phase. The .obt files specify the positions on the screen of the words in your stimuli. They are the missing link between (the XY-coordinates of) your eye-movement data and your visual stimulus.
- If you are running your experiment in Chinese (or any other ideogrammatic script), you will want your .obt files to define areas of interest per character (rather than define words as strings of characters separated by spaces). To accomplish this, you will need to put a space in between the characters.
- Do this on the computer you are going to run the experiment on: the Stimulus PC in K.12the Stimulus PC in K.09the SMI laptop.
- The screendumps are generated by a special script that is available in your experiment folder. In the terminal, run zep quick_show_and_save_pictures.zp to generate .png screenshots of your stimuli.
- Your experiment will open and you will be able to select which group (list) to run it for. The experiment will then ‘fly’ through your stimuli (without waiting for a response) and generate the screendumps for the list you selected.
- Repeat the process for each list.
- The screendumps will be generated in the folder YOUREXPERIMENTFOLDER/data/visworldx/img/GRP1/, YOUREXPERIMENTFOLDER/data/visworldx/img/GRP2/ etcetera, in .png format.
- Move (don’t copy, move!) all the .png files from the GRPX/folders to the img folder (so one level up). If you are warned that you are overwriting files, make sure that this concerns files that should indeed be the same across your lists. Typically, your fillers will be the same across lists, but your experimental items will not be. If experimental item screendumps are overwritten, you may have made a mistake in the coding of the item numbers and/or conditions and/or indexes in your stimulus file, so really pay attention.
- The analysis program Fixation can only handle images in .bmp format, so you will need to convert the images to .bmp. To do this, in the terminal, go to the directory that has the images in it, by typing cd data/visworldx/imgEnter. Then run mogrify -format bmp *.png.
- Finally, move (don’t copy, move!) the img folder to the subfolder you will analyze in Fixation: YOUREXPERIMENTFOLDER/data/YOUREXPERIMENTFOLDER/
5.2 Pilot your experiment
To make sure that you have done everything right, you need to pilot your experiment. Change the experiment status to ‘piloting’ in ZEP, and first run a technical pilot on yourself.
To ensure smooth running of your experiment in case of any network hiccups, run your experiment from the local disk rather than running it from the network drive; carefully follow the instructions in the howto Properly run a ZEP experiment. You will want to run all your ‘real’ participants locally. (for VWP experiments this is more crucial than for reading experiments though).
When that seems OK, run a behavioral pilot with some pilot subjects (ask for some friends’ help). Note: while you are running actual participants, you will want to make sure the red light outside K.07 is burning, to indicate to people outside that they need to be quiet and cannot barge in. The red light comes on when you switch on the light in the kitchen – the light in the experimenter room and in the participant room do not make the red light come on.
Observe the behavior of your pilot subjects and ask what they think of the experiment to gauge whether the task is done by your participants the way you expected.
Then go through all the steps below and look at the response data, the eye movement data, and the Fixation output to double-check all your codings. Do this for all your lists. Also check whether the randomization of your stimuli works as intended.
Double-checking everything before you actually run the experiment may seem time-consuming and tedious now, but it will save you time in the long run.
5.3 Find subjects
If you have similar materials to add that may be useful for others, please let lab support know!
Back to Step 4. Calibration
Up to steps overview
Step 6. Convert and transport your data
Eye movement data
By default, ZEP outputs the eye movement data in .edf files, an EyeLink-defined format. In addition, you can make ZEP output eye movement data in .csv files, in a format controlled by ZEP (specify this in the EyeLink module if desired). Both types of output files will be written to the data/YOURTHREELETTEREXPERIMENTNAME/dat directory.
When you run your experiment with a simulated eye tracker, the .edf format is not available, and you will get the .csv format instead (not that the simulated eye movement data will be of much use to you).
- After you are done running your subject(s), go to the data/YOURTHREELETTEREXPERIMENTNAME/dat directory (cd data/YOURTHREELETTEREXPERIMENTNAME/dat in the terminal) and type python mkasczep.py -gEnter, that is, run the Python script mkasczep.py on all the .edf files in your dat folder. The script converts the .edf files to .asc format, and names the .asc files to a name that is understood by the analysis program Fixation. The general name format for your .edf files is SessionNumber_ListNumber_ParticipantNumber.edf. The name generated by mkasczep.py for the .asc files is Experimentname_ListnumberBlocknumber_Participantnumber.asc.
The SMI fixation detecting algorithm is not ideal: it tends to detect micro-fixations that are very close together as separate fixations, while you would rather have these as one fixation. To fix this, you can process your .asc data file with the program iSpector. iSpector is installed on the SMI laptop in C:\ils-software\iSpector\, as well as on the PCs in K.06. You will need to play around with the parameters a bit; contact Maarten Duijndam for help.
All necessary files will appear in the directory ~/YOURTHREELETTEREXPERIMENTNAME/data/YOURTHREELETTEREXPERIMENTNAME. This directory can be read in in Fixation. It consists of four subdirectories:
- /YOURTHREELETTEREXPERIMENTNAME/dat contains your data files: .edf files (raw data file, contains samples), and .asc files (slightly less raw data file, contains fixations and saccades)
- YOURTHREELETTEREXPERIMENTNAME/obt contains your .obt files (specifying where the wordsareas of interest in your experiment are on the page, plus additional info. See Step 7 below for how to generate .obt files for VWP experiments.
- /YOURTHREELETTEREXPERIMENTNAME/img contains your .bmp files (the screendumps of the pages in your experiment that you generated in step 5.1 above).
- /YOURTHREELETTEREXPERIMENTNAME/result is empty, but provides a place for the result files you will generate in Fixation
In addition, you will need to create two other subdirectories (instructions below in step 7):
- YOURTHREELETTEREXPERIMENTNAME/tim will contain files specifying where the relevant areas of interest are in your sound files
- YOURTHREELETTEREXPERIMENTNAME/wav will contain your sound files
Response data
Go to the YOURTHREELETTEREXPERIMENTNAME ZEP directory (so the higher instance, not the one inside YOURTHREELETTEREXPERIMENTNAME/data), and run zepdb2extract in the terminal. This will generate a file YOURTHREELETTEREXPERIMENTNAME-1-1.csv in your experiment directory. In this file, you find all your subject’s responses (response, response time), and the order in which the trials were presented. Analyze as you see fit.
When you’re done for the day
Power off the equipment in order of sensitivity (the reverse of how you switched them on).
- Close the EyeLink program on the EyeLink Host PC by pressing ctrl-alt-q or clicking ‘Exit EyeLink’ in the ‘Offline’ menu of the EyeLink Host software.
- Switch off the camera (using the switch on the power block).
- Switch off the EyeLink Host PC.
- Switch off the Stimulus PC.
- Switch off the monitors. Switching off the monitor in the participant room will also switch off the EyeLink camera.
- Switch off the laptop. Make sure it is not just sleeping, but actually turned off! If it’s still on when you put it in the flightcase, it may catch fire.
- Disconnect the eyetracker and the external USB screen.
- Put the laptop and the eytracker neatly into the flightcase.
Transport your data to a computer where you can run Fixation
Upload your data to the
ILS Labs data server. You can use Eduroam to connect to the network if you are in the lab.
Use the ILS Labs data server to access your data on a different PC. Working in Fixation will be much faster if you copy your data to a local directory. If you want to use Fixation in K.06, copy your entire experiment data directory to D:\eyetrack\data. (Just copy the directory carrying YOURTHREELETTEREXPERIMENTNAME that has dat, img, obt and resultdat, img, obt, result, tim and wav as immediate subdirectories – NOT your whole ZEP directory!) Don’t forget to upload the result files to the data server when you are done for the day – in K.06 your data can be deleted from the local disk D:\eyetrack\ by anyone!
Back to Step 5. Pilot and prepare for subjects
Up to steps overview
Step 7. Code your critical regions
Your .obt files specify the positions on the screen of the words in your stimuli. They are the missing link between (the XY-coordinates of) your eye-movement data and your stimulus.
In this step, you’ll specify which words make up your critical regions. This is a semi-intelligent task that you’ll have to do by hand. Note: the instructions below instruct you to use TextPad to edit your .obt files. If you use different software, bear in mind that Fixation can only read .obt files that have UTF8 encoding and are space delimited, OR ANSI encoding + tab delimited. UTF8 + tab delimited cannot be read by Fixation.
- Open TextPad. If you’re working on your own PC, you can download TextPad here.
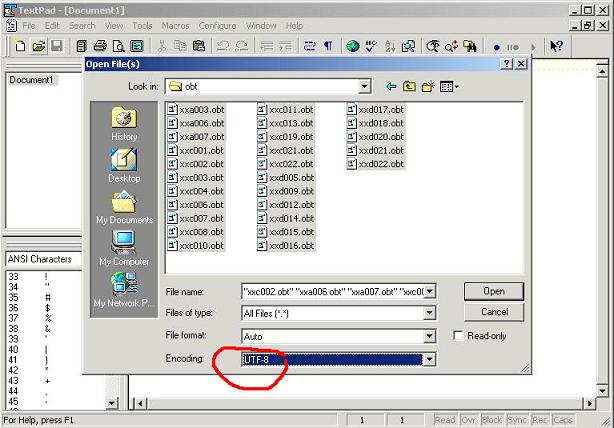
- Open your .obt files. You can read in all your .obt files at once. If you want to avoid character encoding issues (not critical), you can choose to open your .obt files in UTF-8 encoding:
 |
| Screenshot TextPad |
The columns in the obt-files specify the following information about the words in your stimulus:
- object (word)
- object length (number of characters, without spaces)
- object number in line
- number of objects in line
- line length
- object number in text
- line number
- number of lines in the text
- stimulus number
- object x-coordinate (upper left corner)
- object y-coordinate (upper left corner)
- object x + object width (including spaces)
- object y + object height
- object code 1
- object code 2
Column 14 is where you specify your regions.
Do NOT use the number zero to code any region – the code 0 is reserved for ‘unassigned’ fixations in Fixation.
Furthermore, make sure that you number your regions consecutively. Do not, for instance, give all your non-critical regions number a particular number, as this will mess up the aggregation algorithm. So you can do this: 1112233455, but not this: 1112233255.
You may have a region that is present in one condition but not in another, that is fine: you can have something like 11334455 in one condition and 11222334455 in another. So skipping a number altogether is fine.
Create .obt files
Your .obt files specify the positions on the screen of the areas of interest in your stimuli. They are the missing link between (the XY-coordinates of) your eye-movement data and your visual stimulus.
In this step, you’ll specify which parts of your visual stimuli make up your areas of interest. This is a semi-intelligent task that you’ll have to do by hand.
Use the Windows program mkobjects (available in the General Repository and installed in K.06) to code the visual areas of interest. Use of the program is self-explanatory: you just open your .bmp screendump picture, click and drag to mark the areas of interest, and save (as nameofyourpicture.obt – the name has to be identical to the name of the corresponding .bmp file in your img directory).
Open the .obt files in TextPad or Notepad++ (it is highly recommended to use Windows, not Mac OS or Linux) and code the final two columns (default 0) to reflect the content of your areas of interest. Use the final column for spatial location (for instance: top left 1, top right 2) and the penultimate column for the content (for instance: target 1, distractor 2).
Mark points in your sound file (.tim)
The method below outlines how to code your sample data for your auditory stimulus in Fixation. You can of course also choose to write your own scripts to do this.
For each sound file, you’ll create a .tim file in Praat, defining one Text Tier with multiple points of interest marked. Every point will mark the start of a segment in your sound file. Fixation will use the .tim file info to mark a fixation/sample that starts in that segment, with the corresponding point number and mark.
This means that for every segment you are interested in, you need to mark its starting point.
Here’s how to create your .tim files:
- If you specified a ‘AUDITORY_DELAY’ in your ZEP experiment, you will need to insert silence at the start of your .wav files to match the sound delay you specified in your experiment. See above for instructions.
- Read your sound files into Praat.
- Select a sound file in the ‘praat objects’ window.
- Choose ‘annotate’ -> ‘to TextGrid’. A dialog box pops up.
- In ‘all tier names’, type a single word or letter (no spaces, as a space will create an additional tier, and you need only one tier).
- In ‘which of these are point tiers?’ fill out the same word or letter.
- Click OK.
- Select both your Sound and its accompanying Text Tier in the Praat object window, click ‘Edit’.
- To create a point in your tier, click in a sound area (not in the tier!), a circle appears in the tier.
- Click on the circle, it changes into a bar. Drag the bar to place it.
- Repeat for any other points you need to mark (in the same Tier, don’t create a new Tier).
- Also mark the end of the utterance. (See note in point 16 below).
- Mark (name) your points by clicking on them, and typing their name in the white space at the top left of the window. Do not use spaces in the mark name!
- Optional: to name the tier, choose ‘Tier’ (top of the window) and select ‘Rename tier’. You can for instance write out your whole sentence here.
- Save your tim file: File -> Write TextGrid to text file. Change the default .TextGrid extension to .tim
- Note: Fixation will code everything after the offset of your soundfile as timcode 0; this is a problem if you’re interested in the eye movements after the offset of your soundfile, since the samples that are recorded before the start of your stimulus are also coded as timcode 0 (so there is no way to tell samples post-soundfile apart from samples pre-soundfile). One way to get around this is to add silence to the end of your stimulus .wav file as explained above. Alternatively (easier), you can trick Fixation into coding the samples after soundfile offset with a meaningful code, by marking the end of your soundfile with a point, and manually changing the “xmax” value in the .tim file to a larger value (for instance, add 20 seconds to that value to code the samples that appear up until 20 seconds after the offset of your soundfile). Note that the “xmax” variable appears twice in each .tim file.
- Since it takes 150-200ms to plan and execute a saccade, it is customary to analyze eye movements in VWP paradigms from 200ms after the onset of the auditory cue. You can implement this by manually adding 200ms to the onset of each auditory region in your .tim files. (On the other hand, for graphs you may want to plot the development of the looks from the target word onset precisely to show that it takes about 200ms to launch the saccade. So it really depends on what you want to do, and you can also (re)code your samples in R or SPSS of course).
Also see this Praat tutorial for creating texttiers.
Back to Step 6. Convert your data
Up to steps overview
Step 8. Clean up and code your data
The next step is to clean up and code your eye-movement data with Fixation. See the Fixation manual.
Note: The EyeLink algorithm for detecting fixations and saccades is quite good, and it is recommended to stick with what the system gives you. However if you want to change the parameters of what counts as a fixation and what counts as a sample for compatibility with other eyetrackers (for instance if you have run part of your experiment on another brand of eyetracker in a different lab), you can use iSpector. iSpector is installed in K.06. You will need to play around with the parameters a bit; contact Maarten Duijndam for help.
8.1 Practicalities
Fixation is already installed on the PCs in K.06 (in D:\eyetrack\programs). If you want to work at home, you can also download it from the General Repository page.
8.2 Data cleanup
In VWP experiments, you will want to do a visual inspection of your trials, with the aim of removing any trials from analysis that do not seem up to snuff. If all fixations seem to be moved in a certain direction (drift), you can see if you can fix this by moving all fixations. Reassigning individual fixations is not a good idea in VWP (in reading experiments this is routinely done on the basis of properties of the reading pattern, but expectations about fixation patterns in VWP are not so clear). Pay particular attention to the position of the first fixation; you expect it to fall on the position of the drift correction dot, so if it doesn’t, that is also an indication that you may be dealing with drift.
Issues that you deal with at this stage include drift, initial fixations that do not fall on the first word of your stimulus, and blinks. The following gives a general description of the concepts involved; for information on how to work in Fixation, see the manual.
8.2.1 Drift
For some examples of drift in reading data, see slides 80-85 here.
8.2.2 Blinks
Obviously, during a blink, the participant does not actually see the stimulus. Whether the participant is nevertheless processing the visual stimulus during that time, is a matter of debate. Reviewers or editors may or may not feel strongly about this either way; check out what the policy is of the journal you want to publish in. Otherwise, use your own judgment.
Corresponding to the alternative philosophies, there are several ways to deal with fixations containing blinks. You need to think about what your philosophy is before cleaning up all your data, as your clean-up method is severely affected by it. Do look at some trials – it will help you understand the pattern of blinks in your data, which may affect your decision.
- Treat blinks like regular fixations. Simply assign fixations with blinks to the object you think it belongs to.
- Remove blinks. The way to implement this in Fixation, is to unassign any fixation containing a blink. Underlying philosophy: during a blink, a participant is not processing the stimulus at all. This approach treats blinks like they never happened at all. Note: older versions of Fixation, and its forerunner SMIana did NOT treat unassigned fixations like they never happened – while they did exclude the duration of the fixation containing the blink from the first pass measures, they would also ‘cut off’ the first pass measures at this point (tgdur, gdur, rpdur). The only way to ‘pretend blinks never happened’ in these older versions, was to remove them from the .jnf file. Underlying philosophy: unclear. There has been a fairly gradual move towards treating unassigned fixations as if they never happened in the development of the program. Build 15 is the first build of Fixation that completely treats unassigned fixations like they never happened.
- Treat blinks as potentially disrupting events. In Fixation, you can implement this view by removing regions that contain blinks. First, assign blinks to the object you think they belong to. In the .agc files, Fixation gives a special code to every region containing blinks. You can use this code to remove data for regions that contain blinks. The idea is that a blink renders the data for that region invalid. Underlying philosophy: we don’t know what exactly blinks signal, so to be on the safe side, we exclude from analysis any region that has blinks in it.
8.2.3 Initial fixations that do not fall on the first word of your stimulus
Usually, participants will fixate first on the first word in the stimulus, because you’ve directed their gaze to that position by the drift check target preceding the stimulus. Sometimes, however, the first fixation does not fall on the first word. If this fixation is followed by fixations that do fall on the beginning of your text, these later fixations will be seen as second pass fixations. A solution to this is to unassign the first fixation. Use your judgment: for instance, if you have a whole series of initial fixations in the middle of your text, unassigning them will not reflect what actually happened.
Back to Step 7. Code your critical regions
Up to steps overview
Step 9. Prepare your data for analysis
A Python script is available for post processing the data. Here is what the script does:
- it solves the problem that Fixation does not calculate total fixation times for regions. The script processes all your .agc and .jnf files, and for each .agc file outputs an .act file which is your .agc with five extra columns:
- totfixdur: sum of ALL fixation durations in the region (including second, third… nth pass)
- totfixcnt: the number of fixations in 1
- NumFixQualNot0: the number of fixations in 1 that do not have Qual 0 (blinks/rejected fixations)
- totfixQual0dur: sum of all fixations in 1 that have Qual 0
- totfixQual0cnt: the number of fixations in 4
- it writes all your .act files to a single file (allACTFiles.txt) in your result directory, splitting up the planame into condition and item number (so that you get those into separate columns when you read the datafile(s) in in SPSS or R).
- it writes all your .ags files to a single file AllAGSFiles.txt in your result directory, splitting up the planame into condition and item number (so that you get those into separate columns when you read the datafile(s) in in Excel, R, or SPSS).
To run the scripts, once you have assigned all your fixationsevaluated and coded all your data in Fixation, go to one of the PCs in K.06.
- Make sure you have all and only the data files that you want to use in your result directory – no subdirectories with older/discarded data files, for instance, as the script will process these too.
- The files you need are the .ags files if you want to analyze sample data (you probably do), and .agc and .jnf if you want to analyze fixation data rather than sample data (could be useful and quick in some cases, maybe).
- The files you need are the .agc and .jnf files.
- Download the script: right-click this link, choose ‘Save as’, and save it in your result directory.
- Run the script by double-clicking it.
- Watch for errors – the scripts give some rudimentary error messages in the terminal if something doesn’t work as expected.
- Output is written to your result directory.
If you are working from home, rather than on a PC in K.06, you need to install Python 2 or 3. For some more help, for instance on running under Mac OS, see the help here. If something doesn’t work as expected, contact Iris Mulders.
For a full overview of the meaning of the columns in your final data files – allACTFiles.txt for aggregated fixation data and AllAGSFiles.txt for sample data – see the Fixation manual.
Back to Step 8. Clean up and code your data with Fixation
Up to steps overview